
Apache NiFi: Ottimizza la Gestione dei Flussi di Dati in Tempo Reale - RIOS
Apache NiFi: Ottimizza la Gestione dei Flussi di Dati in Tempo Reale
26 luglio 2023
Indice
Introduzione
Cloudera ha di recente annunciato, tramite un apposito webinar le principali novità che saranno presenti nella prossima major release di NiFi (la 2.0): è un’ottima occasione per descrivere brevemente quali sono le caratteristiche principali dell’ambiente focalizzandoci successivamente sulle prime indiscrezioni su quanto di nuovo ci fornirà la release che attualmente è in fase di avanzato sviluppo.
Panoramica di Nifi
Apache NiFi è una piattaforma open source per la gestione e il flusso dei dati in tempo reale. Consente agli utenti di definire, tramite un'apposita ide, workflow per l'acquisizione, il trasferimento, la trasformazione e la gestione dei dati provenienti da diverse fonti con il supporto per la scalabilità e la ridondanza tramite l'utilizzo di configurazioni in cluster. Grazie alla sua scalabilità NiFi è infatti in grado di elaborare grandi volumi di dati e di integrarsi con diversi sistemi e protocolli; tra le funzionalità avanzate che mette a disposizione la piattaforma annoveriamo la sicurezza e la gestione del flusso dati. L’approccio visuale ai flussi è basato su entità elaborative collegate da code, su cui è possibile interagire graficamente durante l’esecuzione del flusso; ciò consente in fase di debug di apportare allo stesso modifiche e variazioni durante l’esecuzione (Fig.1).
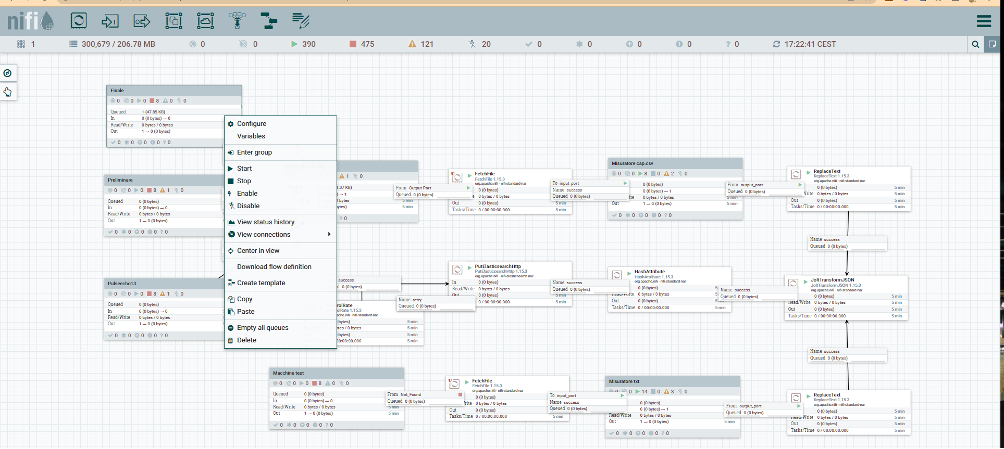
(Fig.1) Approccio visuale dei flussi
Caratteristiche principali della soluzione
Apache NiFi è un sistema di elaborazione dei dati open source che consente di acquisire, instradare, trasformare e analizzare dati provenienti da diverse fonti. Ecco alcune delle sue caratteristiche principali:
Flusso di dati: NiFi è basato su un modello che utilizza flussi di dati. Gli stessi vengono elaborati in tempo reale man mano che si spostano attraverso il sistema.
Modularità: NiFi è altamente modulare e permette l'aggiunta e la rimozione di componenti senza interrompere il flusso di dati.
Scalabilità: NiFi è altamente scalabile e può gestire grandi quantità di dati in modo efficiente scalando sia verticalmente che orizzontalmente (Fig.2).
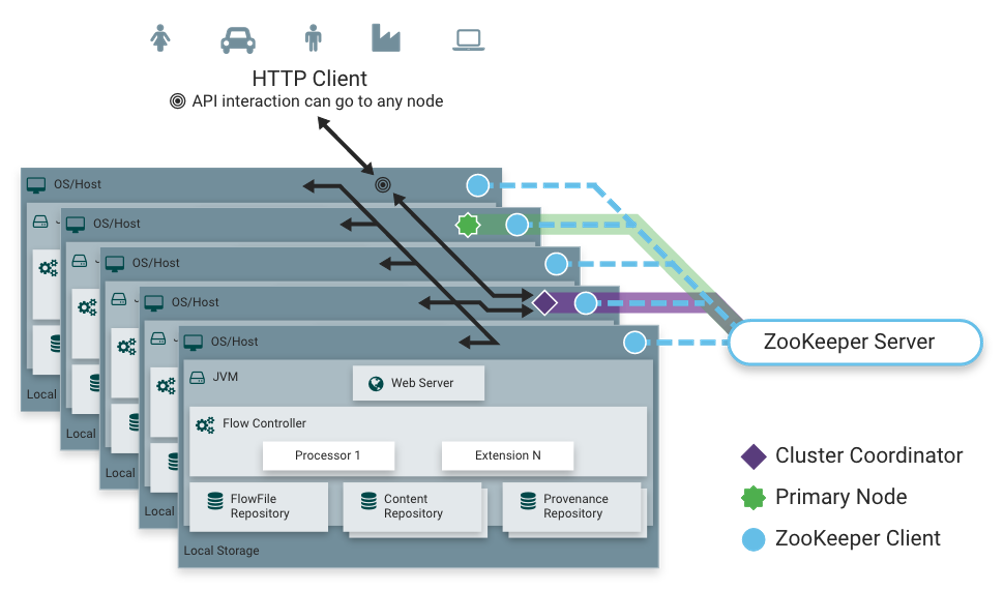
(Fig.2) Scalabilità di NiFi
Sicurezza: NiFi offre una vasta gamma di funzionalità di sicurezza, tra cui l'autenticazione, l'autorizzazione e la crittografia dei dati.
Interfaccia utente grafica: NiFi ha un'interfaccia utente grafica intuitiva che consente agli utenti di progettare, monitorare e gestire i flussi di dati in tempo reale.
Gestione del flusso di lavoro: NiFi consente di gestire e controllare i flussi di lavoro in modo flessibile e dinamico, grazie alla possibilità di creare e configurare facilmente flussi di lavoro complessi.
Supporto per diverse fonti di dati: NiFi supporta diverse fonti di dati, tra cui sensori IoT, database, sistemi di messaggistica, file system, API web e molto altro ancora.
Riassumendo, NiFi è una piattaforma di elaborazione dei dati altamente flessibile, modulare e scalabile che consente di acquisire, instradare, trasformare e analizzare dati provenienti da diverse fonti, in modo sicuro e in tempo reale.
Minifi, la soluzione per l’edge computing nell’ecosistema nifi
Apache NiFi offre anche la possibilità di utilizzare e integrare istanze di Apache MiNiFi quali agent in prossimità alle sorgenti del dato. MiNiFi è una versione più leggera e più adatta all'edge computing rispetto a NiFi, essa può essere installata su dispositivi edge per l'acquisizione dei dati.
Tramite l’utilizzo di MiNiFi, è possibile elaborare i dati localmente prima di inviarli al flusso di lavoro centrale gestito da NiFi. Ciò contribuisce a ridurre la quantità di dati che deve essere inviata a un flusso centralizzato NiFi, migliorando le prestazioni, riducendo i costi di rete e decentralizando il carico computazionale. Inoltre, l'utilizzo di MiNiFi consente anche di utilizzare le funzionalità di NiFi per l'elaborazione dei dati anche su dispositivi da connettere con la installazione centrale ma che abbiano risorse limitate.
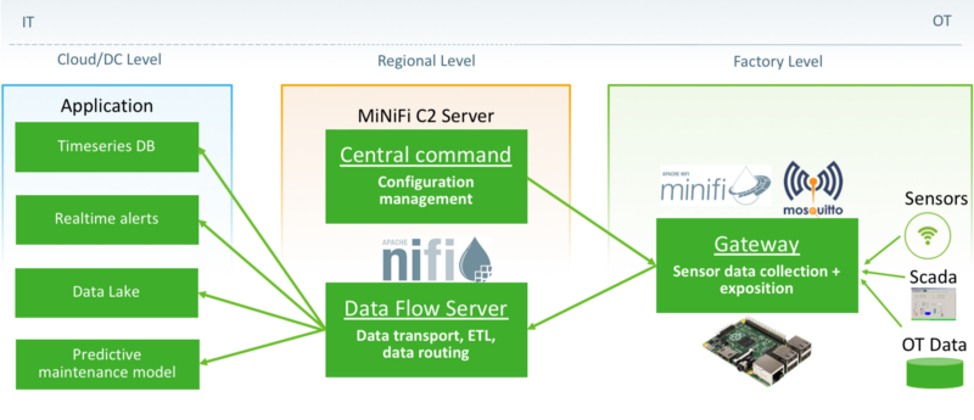
(Fig.3) MiniFi
In sintesi, l'utilizzo di istanze di Apache MiNiFi come agenti consente di estendere la gestione dei flussi di dati anche ai dispositivi "edge", consentendo un'elaborazione più efficiente e scalabile dei dati in tempo reale.
Le componenti principali di NiFi
Passiamo ad elencare le principali componenti che costituiscono gli elementi base attraverso cui vengono implementati e gestiti i flussi di elaborazione NiFi:
- Processor: i processor rappresentano le unità di elaborazione principali in un flusso di lavoro NiFi. Eseguono le operazioni di acquisizione, trasformazione e invio dei dati.
(Fig.4)
- Flowfile: è un'unità di dati in NiFi che rappresenta un singolo flusso di dati in un flusso di lavoro. I flowfile contengono i dati stessi, nonché le informazioni di contesto e metadati associati.
(Fig.5)
- Connection: le connessioni definiscono come sono interconnessi i vari processor in un flusso di lavoro NiFi. Le connessioni possono anche includere informazioni sulla priorità dei dati e su come devono essere elaborate.
Flow Controller: il flow controller gestisce l'avvio, l'arresto e la configurazione dei flussi di lavoro NiFi. Si occupa anche della gestione degli errori e delle eccezioni.
Input e Output Ports: le porte sono i punti di ingresso e uscita del flusso di dati in NiFi. Consentono la connessione a fonti di dati esterne o a destinazioni, come sistemi di archiviazione o di analisi.
Funzionalità di monitoraggio e gestione: NiFi offre un'ampia gamma di funzionalità di monitoraggio e gestione, inclusi dashboard e strumenti per l'analisi delle prestazioni e la diagnostica degli errori.
I principali campi di applicazione
Apache NiFi trova applicazione in molteplici campi, ma il suo principale ambito di applicazione è la gestione dei flussi di dati in tempo reale. Con la crescente quantità di dati generati da fonti diverse, come sensori IoT, dispositivi mobili e social media, NiFi aiuta a gestire e elaborare i dati provenienti da queste fonti in modo efficiente e scalabile.
NiFi è particolarmente utile per l'elaborazione di flussi di dati complessi e la sua capacità di integrarsi con diversi sistemi e protocolli rende l'elaborazione dei dati più flessibile e versatile. Inoltre, NiFi è anche utilizzato in applicazioni in ambito security, per la gestione di log e per la sincronizzazione di dati tra sistemi diversi. NiFi può quindi essere utilizzato in qualsiasi contesto in cui la gestione e l'elaborazione dei dati in tempo reale è fondamentale per il successo dell'applicazione.
NiFi 2.0: cosa c'è di nuovo
Il problema dei processor “mancanti”
NiFi è fornito “out of box” con un vasta collezione di processor in grado di coprire una vasto ambito di sorgenti, elaborazioni e trasformazioni. Non sempre è tuttavia possibile trovare, malgrado un accurato lavoro di progettazione e valutazione, il processor utile per potere adempiere una determinata funzione nel flusso.
Ad esempio non sono disponibili processor che possano effettuare query ldap o richieste xml-rpc o soap. Le strategie adottate, fino ad oggi per risolvere il problema erano essenzialmente le seguenti:
- Utilizzo di processor di “più basso livello” per implementare le chiamate nel caso di protocolli ad esempio chiamate http per i protocolli xml-rpc o soap con appositi payload ed header.
- Esecuzione di script esterni su filesystem (p.e. in python o sh) tramite processor ExecuteStreamCommand, da cui viene acquisito e parsato lo standard output, in tal caso si ha una integrazione abbastanza leggera poiché il sistema non è in grado di avere accesso ad altre informazioni durante l’elaborazione del comando, che viene eseguito su una shell separata.
- Implementazione di porzione di script all’interno di processor ExecuteScript che si integrano tramite degli oggetti alle sessioni ed ai flussi in ingresso e uscita.
Le prime tre soluzioni non prevedono la possibilità di realizzare comunque qualcosa che abbia le stesse modalità di interazione utente dei processor custom (p.e. non è possibile definire delle proprietà ad hoc che rispecchino le esigenze di utilizzo del processor); nel caso in cui si voglia realizzare qualcosa di più “integrato” e simile ai processor standard rilasciati nelle distribuzioni nifi occorre affidarsi alla realizzazione di un processor custom in java.
- La realizzazione di processor custom in java, tramite appositi archetipi maven, comporta la implementazione e il debug dello stesso su ambiente esterno al fine di ottenere tramite compilazione un file nar (pacchetto utilizzato da nifi per installare i processor al suo avvio). L’utilizzo nell’ambiente implica la sua installazione e il riavvio di nifi; operazione da eseguire su tutti i nodi di un eventuale cluster con un successivo riavvio. Ovviamente il processor deve essere successivamente mantenuto e aggiornato nel caso di cambiamento di versione di nifi.
I processor “python”
Dalla panoramica fatta nel paragrafo precedente possiamo dedurre che sicuramente la soluzione è estendibile e customizzabile ma, fino ad ora ci sono anche dei punti di attenzione da valutare quando si decide di implementare o utilizzare un nuovo oggetto che consenta di interagire con sistemi non nativamente supportati dall’ecosistema nifi.
Con la versione 2.0 qualcosa cambia in tale panorama: vengono introdotti i processor python che si affiancano a quelli in java; questi ultimi vengono inclusi e gestiti a tutti gli effetti come processor nativi da NiFi.
Sostanzialmente viene integrato in NiFi un engine che utilizza python per eseguire il sorgente dei processor, la definizione di tutti gli elementi costitutivi del processor viene fatto utilizzando degli oggetti python che rimappano, in maniera simile a java, tutti gli elementi grafici e funzionali dei processor all’interno dell’ecosistema nifi.
La realizzazione di processor custom comporterà ora solo la necessità di implementare un file python con gli appositi import e le necessaria logica per la funzionalità desiderata utilizzando gli skill relativi alla programmazione in python e gli oggetti nifi importati.
Il salvataggio del sorgente python nella apposite cartelle in nifi che ospita tali tipo di estensioni metterà a disposizione i nuovi processor custom.
Senza alcun riavvio o configurazione il nuovo processor e quindi disponibile per essere utilizzato nei flussi, dopo la sua implementazione è possibile modificarlo “al volo” durante l’esecuzione del flusso. Occorre unicamente stoppare il processor stesso, modificare il file python corrispondente salvandolo: con lo stesso paradigma utilizzato per i debug dei flussi ora è possibile eseguire il debug dei propri processor custom.
E’ sicuramente una rivoluzione in termini di tempi di implementazione e accuratezza del debug, come ogni innovazione occorre tuttavia porre attenzione a come viene utilizzata. Più nello specifico chi implementa il processor custom deve essere cura a non snaturare l’utilizzo della piattaforma e deve programmare lo stesso in maniera congruente alla “filosofia dell’ambiente”: il processor deve sempre e comunque rimanere elemento quanto più possibile semplice e atomico solo così sarà possibile preservare le peculiarità dell’ambiente.
In altri termini il processor custom deve essere solo il “mattone” su cui si implementa il flusso elaborativo rispettando il sistema su cui va ad essere integrato e non deve mai essere usato come scorciatoia per realizzare tutto o gran parte del processo rischiando di perdere flessibilità gestione e controllo del flusso.
Stateless nifi
La caratteristica principale di NiFi è quella di “disaccoppiare” i dati in ingresso con quelli all’uscita del flusso di elaborazione attraverso l’uso delle code; l’utilizzo degli stati consente di persistere i contenuti delle varie code. Nel caso in cui per qualche motivo il sistema vanga riavviato è in grado di ripartire esattamente dal punto in cui era stato fermato, sostanzialmente si ha la gestione di singole transazioni per ogni esecuzione di ogni processor. Tale configurazione non consente di gestire tutti quei casi in cui è necessario un rigido accoppiamento tra “l’ingresso” e l’uscita del flusso per cui la transazione deve essere estesa all’intera esecuzione del flusso e non al singolo step (sostanzialmente non devo ritenere il dato committato se non è passato senza errori da tutti gli step del flusso).
Fin dalla 1.15 è stato previsto un meccanismo per gestire il funzionamento “stateless” di nifi che tenesse conto di tale esigenza: con un processor particolare e l’utilizzo del nifi-registry (per indicare il gruppo che dovesse soddisfare a questa condizione) si riusciva a far si che i flussi all’interno di un gruppo fossero eseguiti in modalità stateless. Anche se tale funzionalità era migliorativa rispetto alle precedenti versioni restava comunque un po' macchinosa nella configurazione, oltre che necessitare della installazione di nifi-registry.
Con la nuova versione 2.0 è prevista la possibilità all’interno della configurazione del gruppo di flussi la possibilità di definire se lo stesso debba essere eseguito in modalità stateless o meno.
I template
Il template è una rappresentazione di un insieme di processor che può essere utilizzato come modello per duplicare lo stesso insieme varie volte o, eventualmente fare una copia dello stesso per ripristini e backup.
Storicamente il template è nato come rappresentazione in formato xml della struttura di un flusso, nelle ultime versione è stata introdotta la possibilità di esportare il contenuto di un gruppo di flussi in formato json. Con la versione 2.0 verrà abbandonata la serializzazione dei flussi in formato xml per la creazione dei template e il concetto stesso di template e rimarrà unicamente la possibilità di utilizzare il json per la rappresentazione dei flussi.
Altro
- Rimozione delle variabili all’interno di un gruppo in favore del parameter context per memorizzare le informazioni condivise all’interno di un gruppo di flusso.
- Passaggio alla versione 17 di java.
Conclusioni
In conclusione, Apache NiFi è una soluzione completa e altamente scalabile per l'elaborazione dei flussi di dati. Grazie alla sua flessibilità, affidabilità e capacità di gestire grandi quantità di informazioni, è la scelta ideale per organizzazioni di diverse dimensioni e settori, consentendo loro di ottimizzare i processi, integrare dati eterogenei e garantire la sicurezza delle informazioni in transito.